Milestones
2025
30th August 2025
Redesign of landing pages
In order to better explain Fundamental Theory building and how this platform works the Home-, About- and News- pages were redesigned:



16th May 2025
New video: "Make Measurable Progress"
This New video shows how Fundamental Theory Building allows the social sciences to move away
from making individual, disjoint ad-hoc investigations of specific phenomena and towards collaboratively working on a powerful, shared fundamental theory.
18th April 2025
New video: "How it Works"
This New video gives a general introduction to Tree of Knowledge and explains all the basic concepts and ideas that make this technology work
16th March 2025
New video: "Overview of Advantages"
This video compares the fundamental theories that are created in Tree of Knowledge to conventional statistical models and explains the 10 biggest advantages of fundamental theories
2024
3rd November 2024
New video: "Filter out the Noise"
In this video the biggest obstacle to studying complex systems is explained: not being able to isolate phenomena and the resulting noise. The video also shows how Tree of Knowledge can help deal with this obstacle and thereby open up many areas of research that have sofar been too complex to study
12th October 2024
New video: "Reliable & Universal Insights "
This video shows what a game changer Fundamental Theory Building is: where conventional statistics leads to very unreliable findings (see replication crisis), fundamental theories are highly reliable, rigorously proven and universal
11th May 2024
New video: "How it works v1 "
This video is the predecessor of the "How it works" video published on 18th April 2025. It's not quite as good as misses a good Intro.
Creating this video involved learning to use the softwares: Inkscape (for vectorgraphics) and Sozi (vectorgraphic animation).
Creating this video involved learning to use the softwares: Inkscape (for vectorgraphics) and Sozi (vectorgraphic animation).
7th April 2024
New video: "Building Exact Social Sciences"
This video looks at what is special about exact/hard sciences and shows how the Fundamental Theory Building approach is able to produce exact Social Sciences.
Creating this video involved learning to use the softwares: Blender, Elevenlabs and VideoPad Editor.
Creating this video involved learning to use the softwares: Blender, Elevenlabs and VideoPad Editor.
2023
2022
2021
March - November 2021
Practical application in research
The software Tree of Knowledge was used in two different research projects:
- A project involving modelling people's satisfaction in doing tasks of varying complexity, resulting in this paper
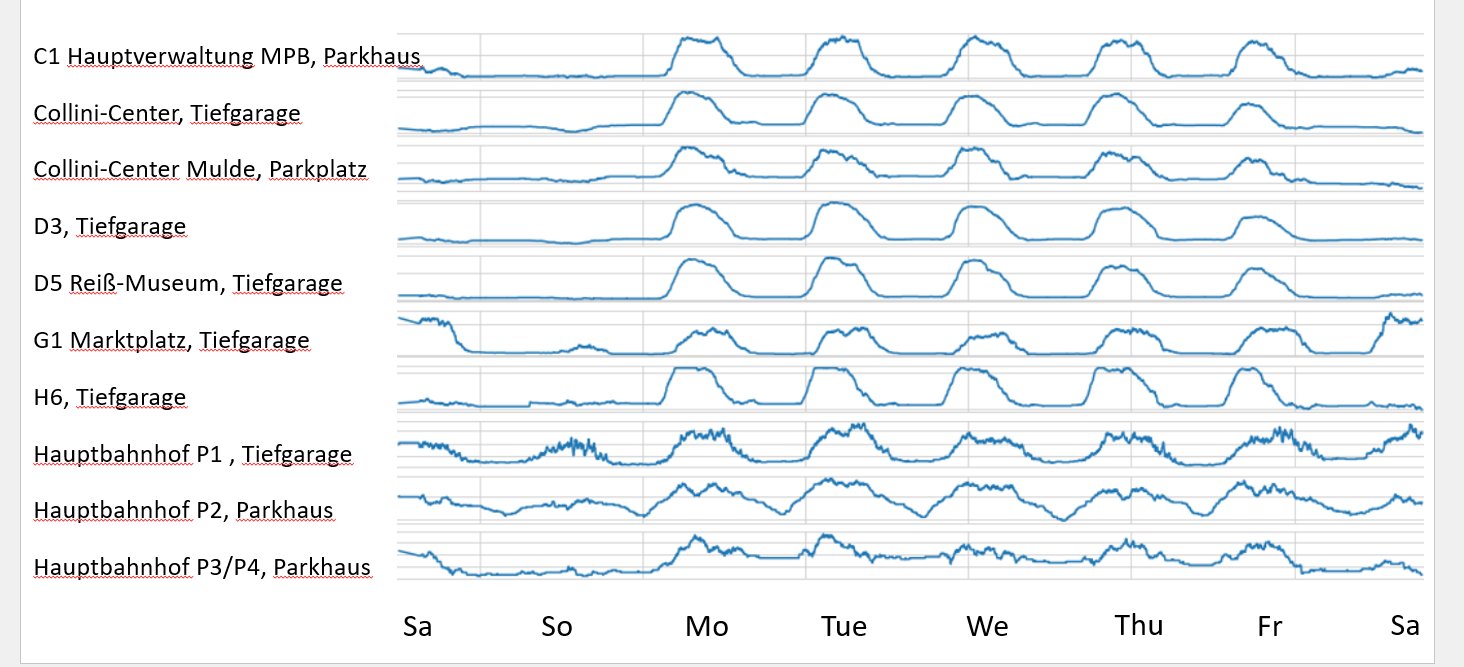
- This other project focussed on traffic simulation

Jan - August 2021
Creating 6 new videos
In order to explain the novel Fundamental Theory Building approach and it's overwhelming advantages, six different videos were created, each highlighting a different aspect of this approach.
These are:
"Inspired by human understanding"
This video shows how Tree of Knowledge mimicks the way we humans create models of how the complex and hidden inner mechanisms of people work. It compiles and reconciles many different experiences in the same way.2-minute-long introduction video
"Advantages for Data Scientists"
This video looks at all kinds of models that are available to data scientists, specifically those focused at gaining an understanding of the underlying system."Advantages for Psychologists"
This video focuses on the advantages for Psychologists such as:
- getting robust & generalisable results by combining many studies
- being able to use observational datasets
- having your findings be used in many fields
"Advantages for Sociologists"
This video highlights the advantages of doing Approximate Bayesian Computation for agent-based models and the immense value if you reuse the same agents in many models."Overview"
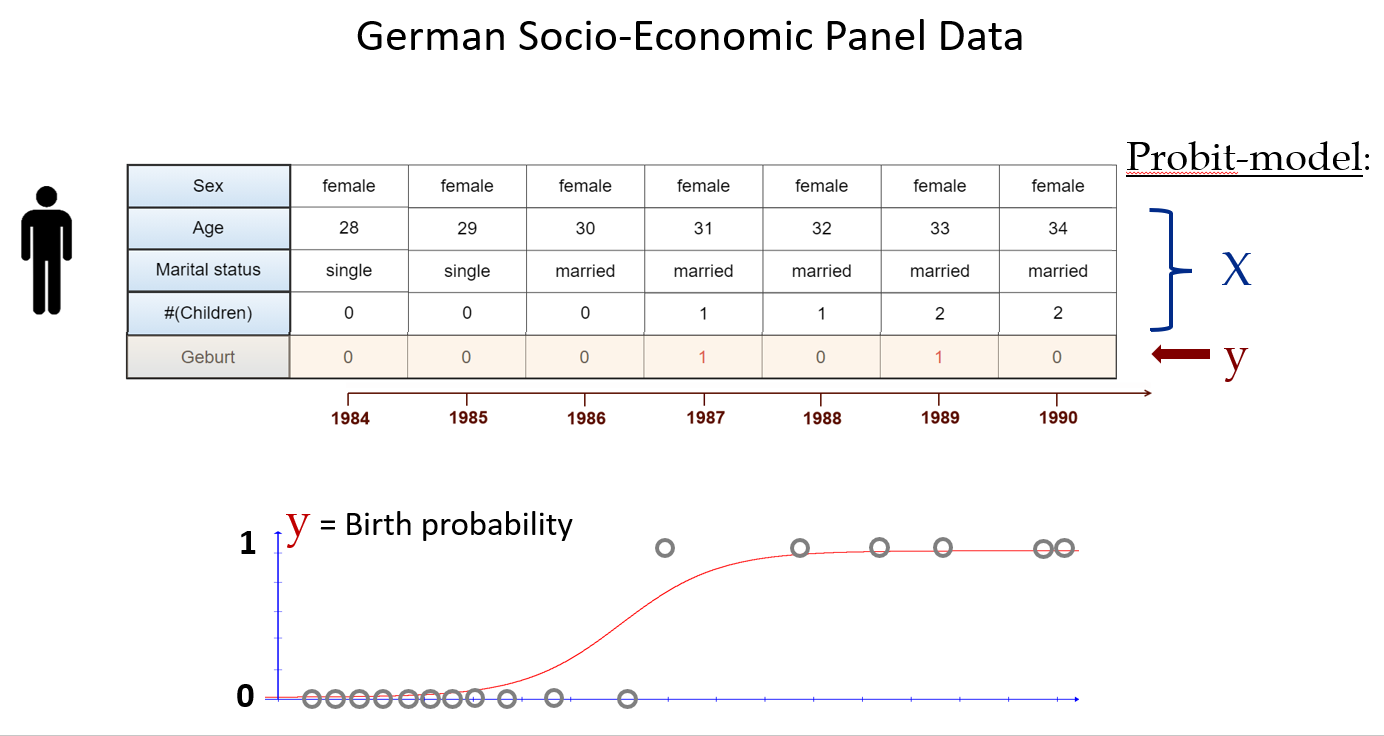
This video provides an overview of how tree of knowledge works. The different functionalitites are explained, using the example of determining the probability of a women to birth a child in any given year.Jan 2021
Autoscaling worker pool for large-scale parallelization
For doing Bayesian Inference, Tree of Knowledge has to run simulations over and over again with different parameter values. For large simulations and simulations with many unknown parameters, this can take quite some time.
To speed up this process, I implemented an architecture where the Tree of Knowledge backend puts simulation tasks on a celery queue and there is a pool of workers (servers) that take tasks from the queue and run the simulations - see diagram below.
If the simulation is very big, then automatically further workers are started and join in.
The code for these workers can be found in this GitHub repository.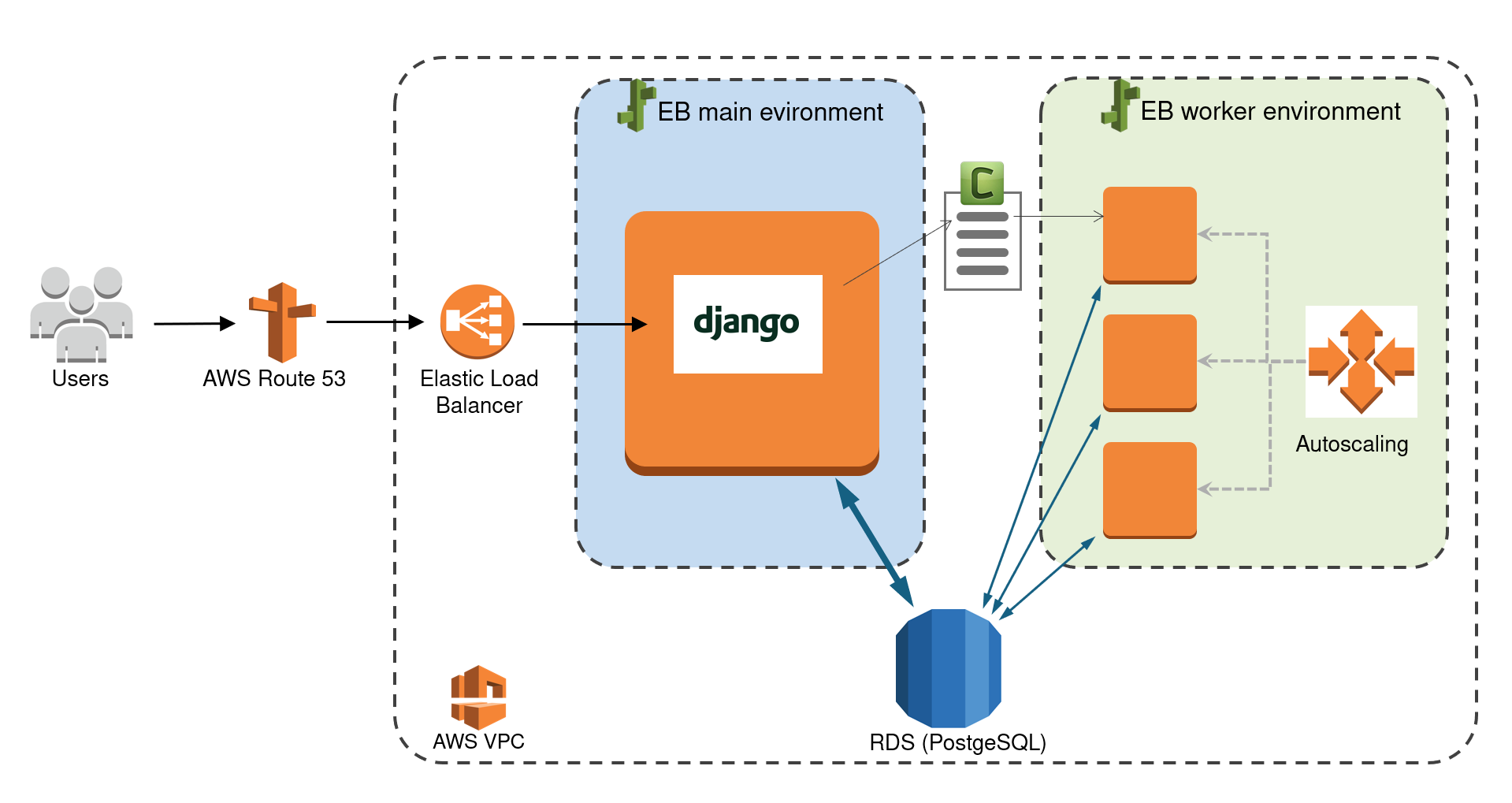
To speed up this process, I implemented an architecture where the Tree of Knowledge backend puts simulation tasks on a celery queue and there is a pool of workers (servers) that take tasks from the queue and run the simulations - see diagram below.
If the simulation is very big, then automatically further workers are started and join in.
The code for these workers can be found in this GitHub repository.
2000
15th October 2020
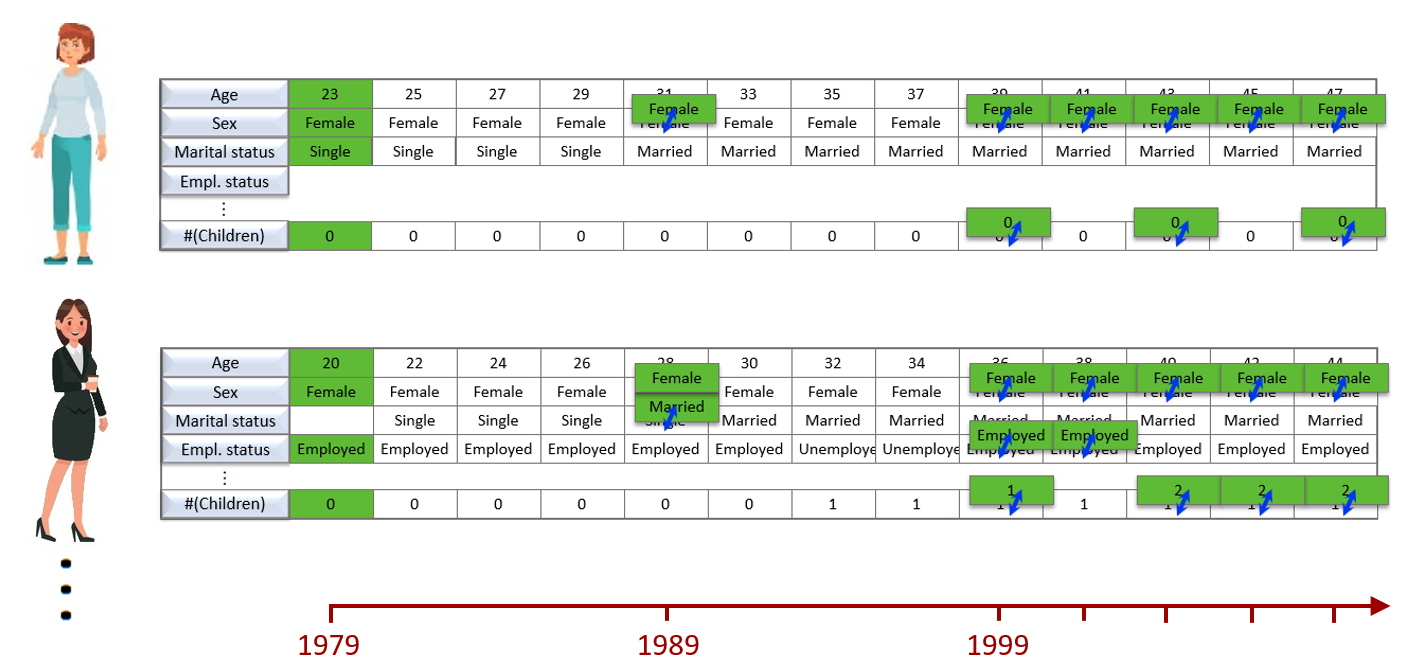
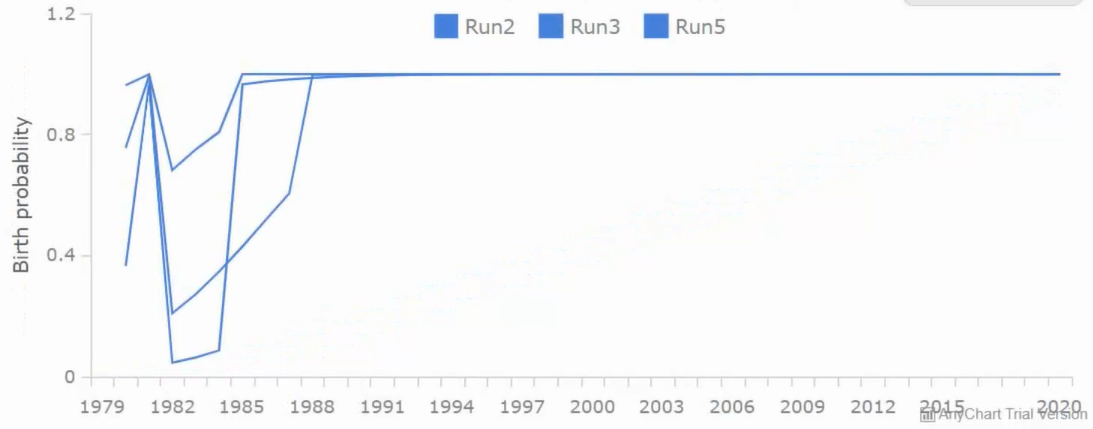
Practical application: Birth probabilities
There already had been great work done in modelling the probability of a woman to give birth to a child in any given year.
For example, this research used a dataset called the "National Longitudinal Survey of Youth" to model this "birth probability".
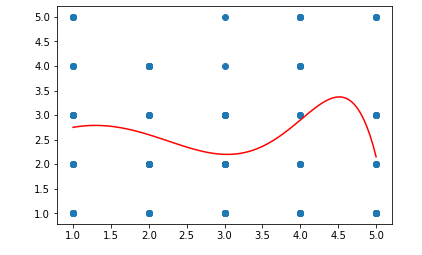
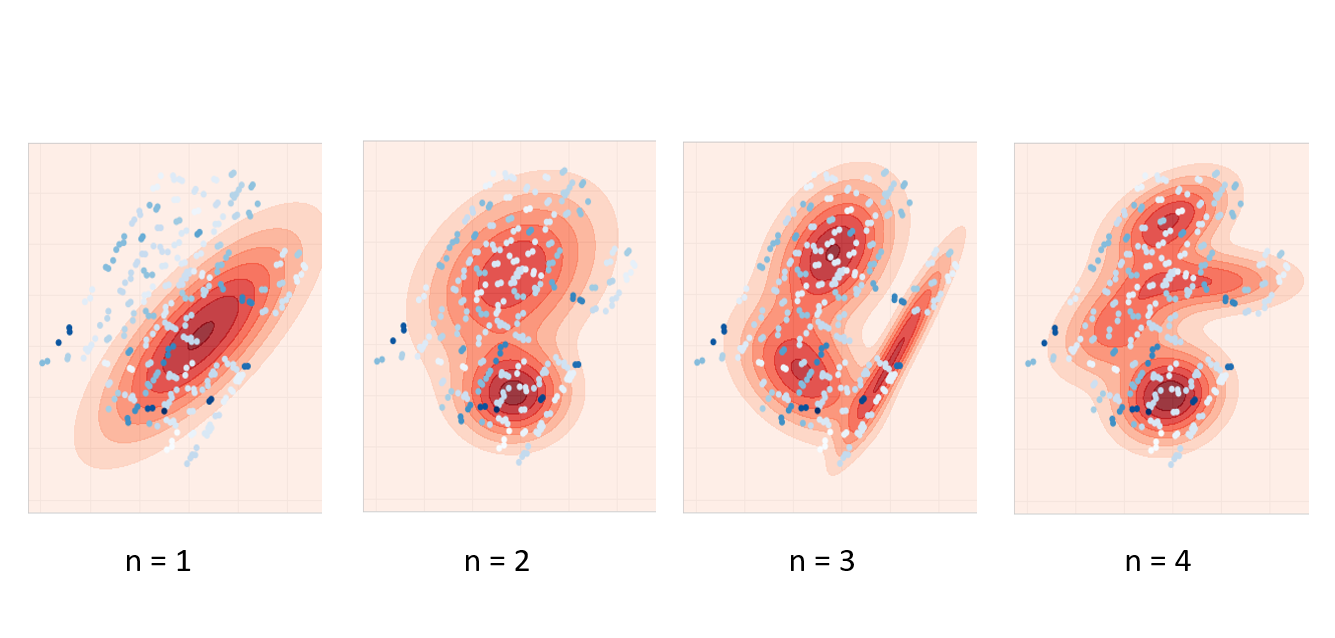
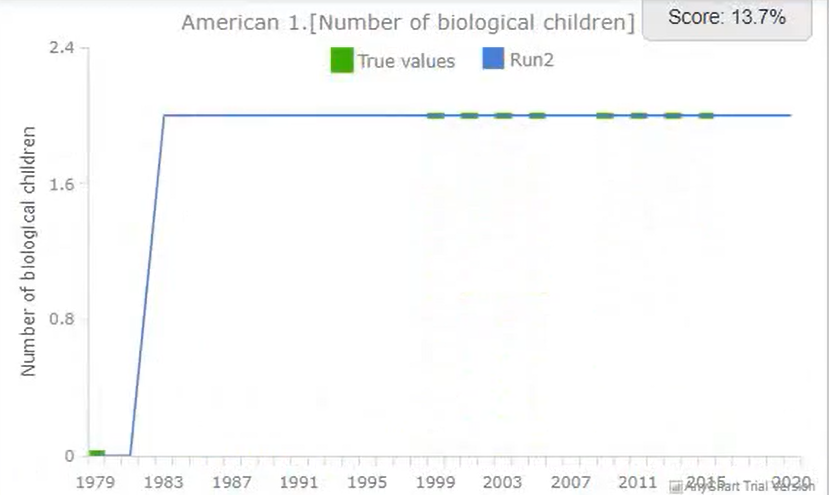
In order to demonstrate Tree of Knowledge's ability to get more accurate and reliable insights by training on multiple datasets, a very basic test was done - the same birth probability was modelled, but was trained on two datasets instead of the one: You can see that this is very different to a meta analysis, as the two datasets are very different: the National Longitudinal Survey of Youth contains data on individual people; the fertility rate data contains data on age-range-groups.
The test was a success, you can see some of the results below.
In order to demonstrate Tree of Knowledge's ability to get more accurate and reliable insights by training on multiple datasets, a very basic test was done - the same birth probability was modelled, but was trained on two datasets instead of the one: You can see that this is very different to a meta analysis, as the two datasets are very different: the National Longitudinal Survey of Youth contains data on individual people; the fertility rate data contains data on age-range-groups.
The test was a success, you can see some of the results below.
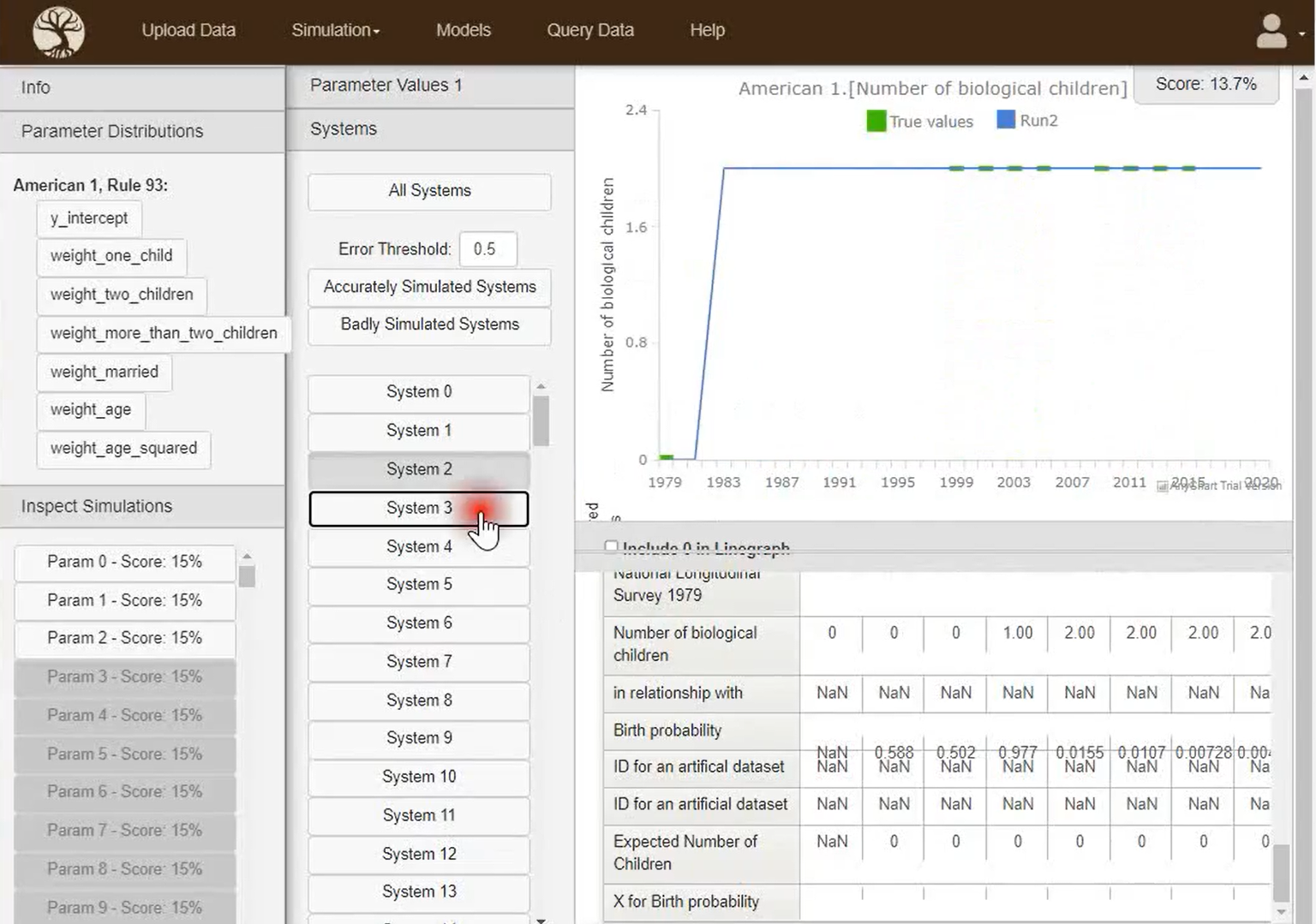
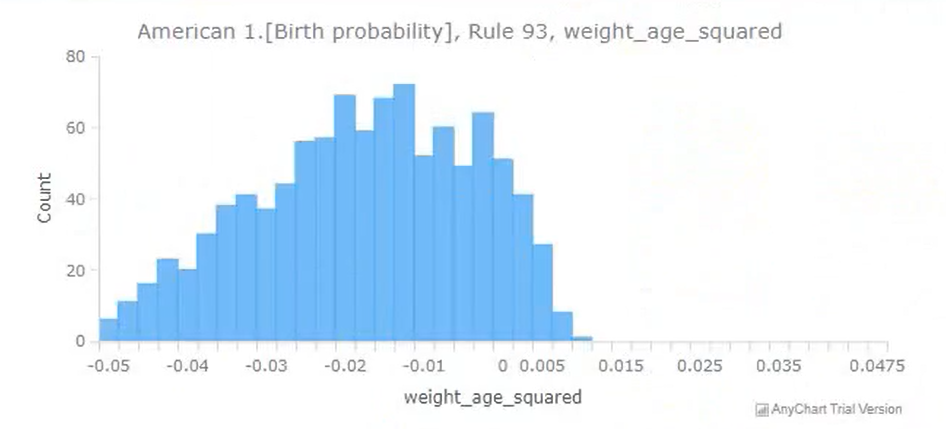
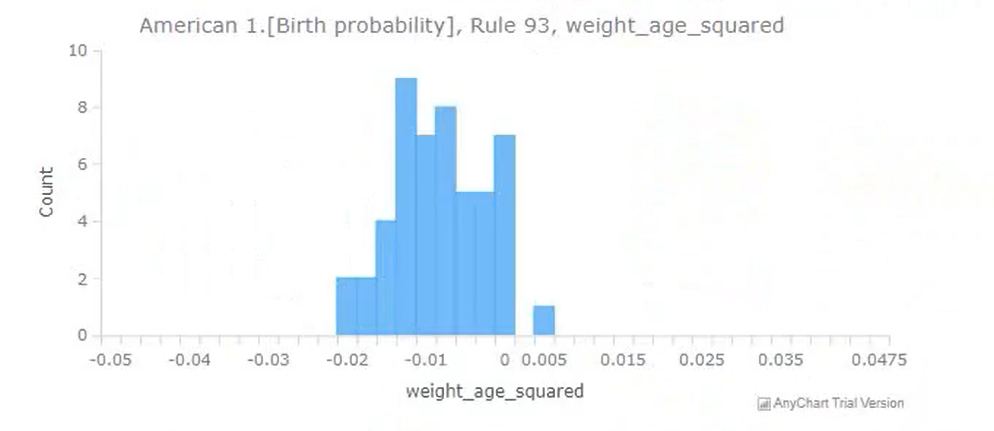
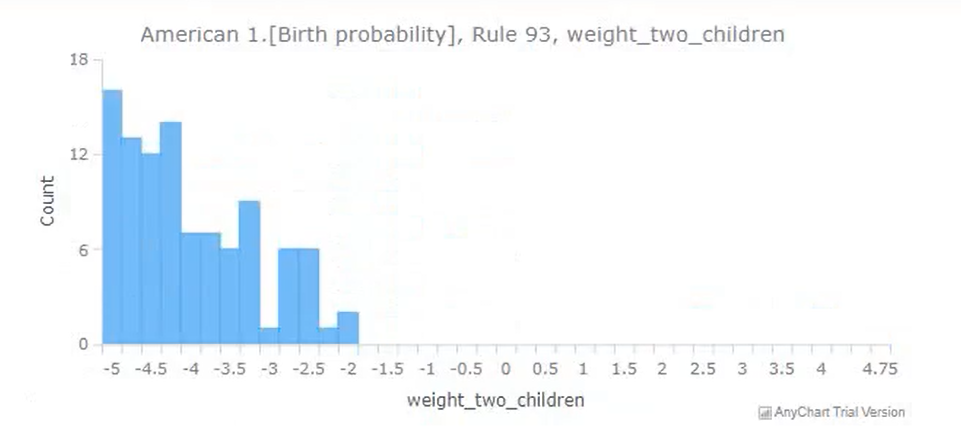

3rd July 2020
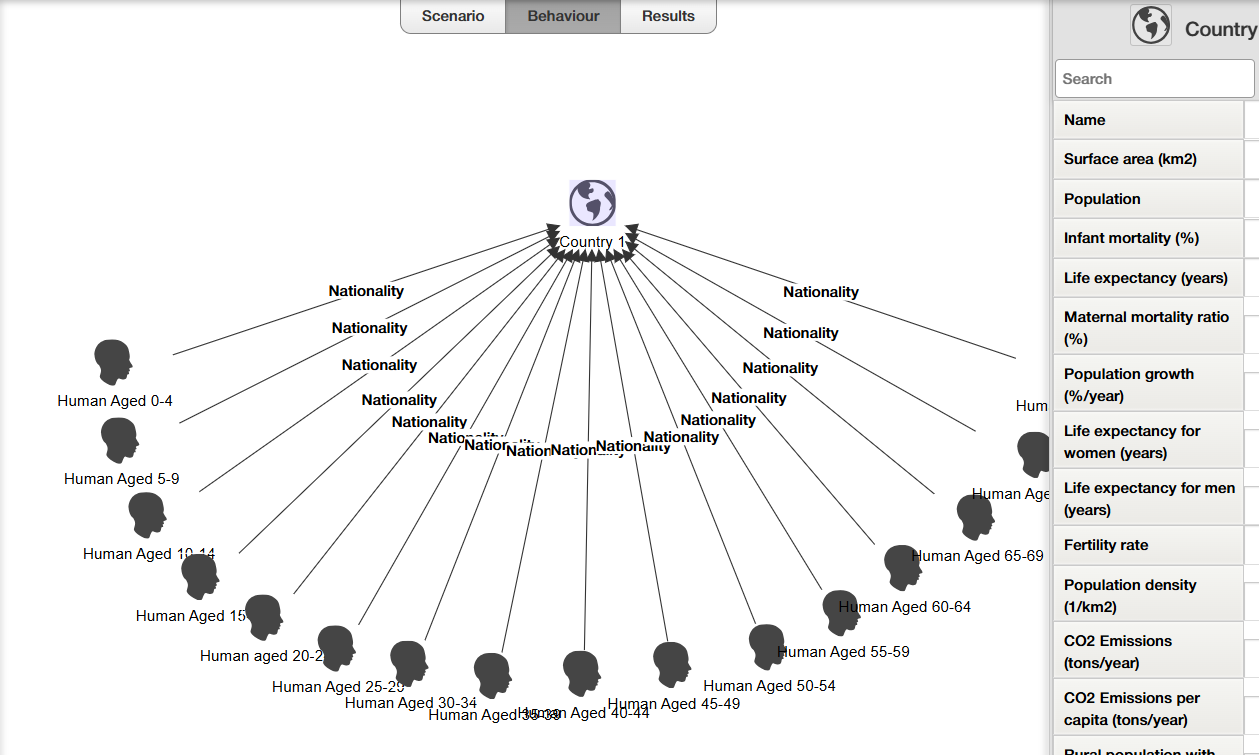
Enable more complex behavior rules
Behavior rules calculate the next timestep's value for a variable, using any of the current actor's own attributes or attributes of an agent related to the current actor.
When creating behavior rules you had the option to use one or more of the following options:
New option "Aggregation"
This allows variables such as a country's "Average fertility rate" to be calculated as aggregated value from many people/population groups.
New option "Random Number"
This allows for random values anywhere in the rule - see example below. The number is drawn from a uniform distribution between 0 and 1. This allows variables such as a country's "Average fertility rate" to be calculated as aggregated value from many people/population groups.
When creating behavior rules you had the option to use one or more of the following options:
- "If Condition" - condition that has to be satisfied for the rule to fire
- "Parameters" - unknown rule parameters that will be inferred using Bayesian Inference
- "Uncertain/Probabilistic rule" - probability for the rule to trigger; also inferred with Bayesian Inference
New option "Aggregation"
This allows variables such as a country's "Average fertility rate" to be calculated as aggregated value from many people/population groups.
New option "Random Number"
This allows for random values anywhere in the rule - see example below. The number is drawn from a uniform distribution between 0 and 1. This allows variables such as a country's "Average fertility rate" to be calculated as aggregated value from many people/population groups.

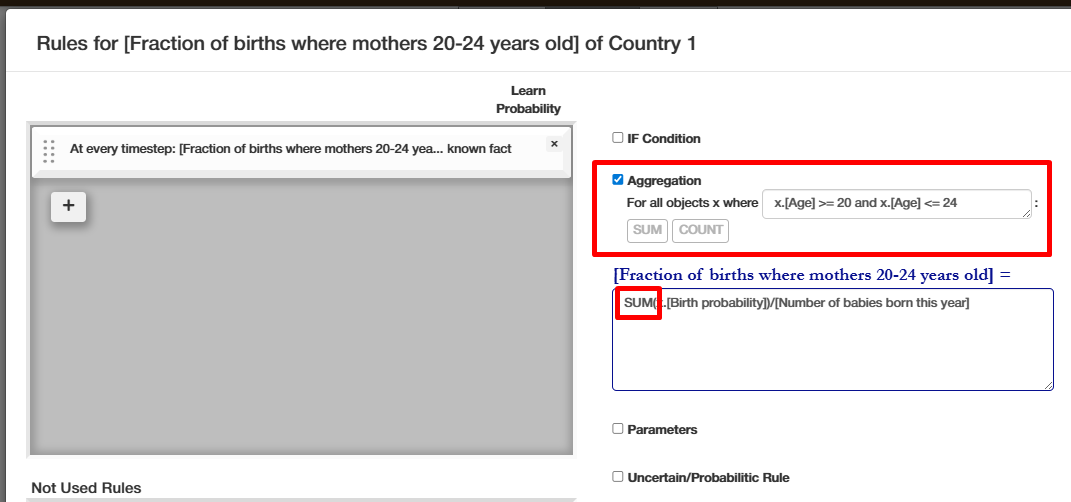

In the above example, [Birth probability] is a value between 0 and 1 that gives the probability of a woman to give birth this year.Let's say, that the [Birth probability] is 0.05 (i.e. a 5% chance to give birth this year).
Now, every year this rule is executed once and everytime a new randomNumber between 0 and 1 is drawn.
This means that for any given year there is a 5% chance that the condition is fullfilled (randomNumber < [Birth probability]) and the woman's number of children is incremented by one
12th November 2019
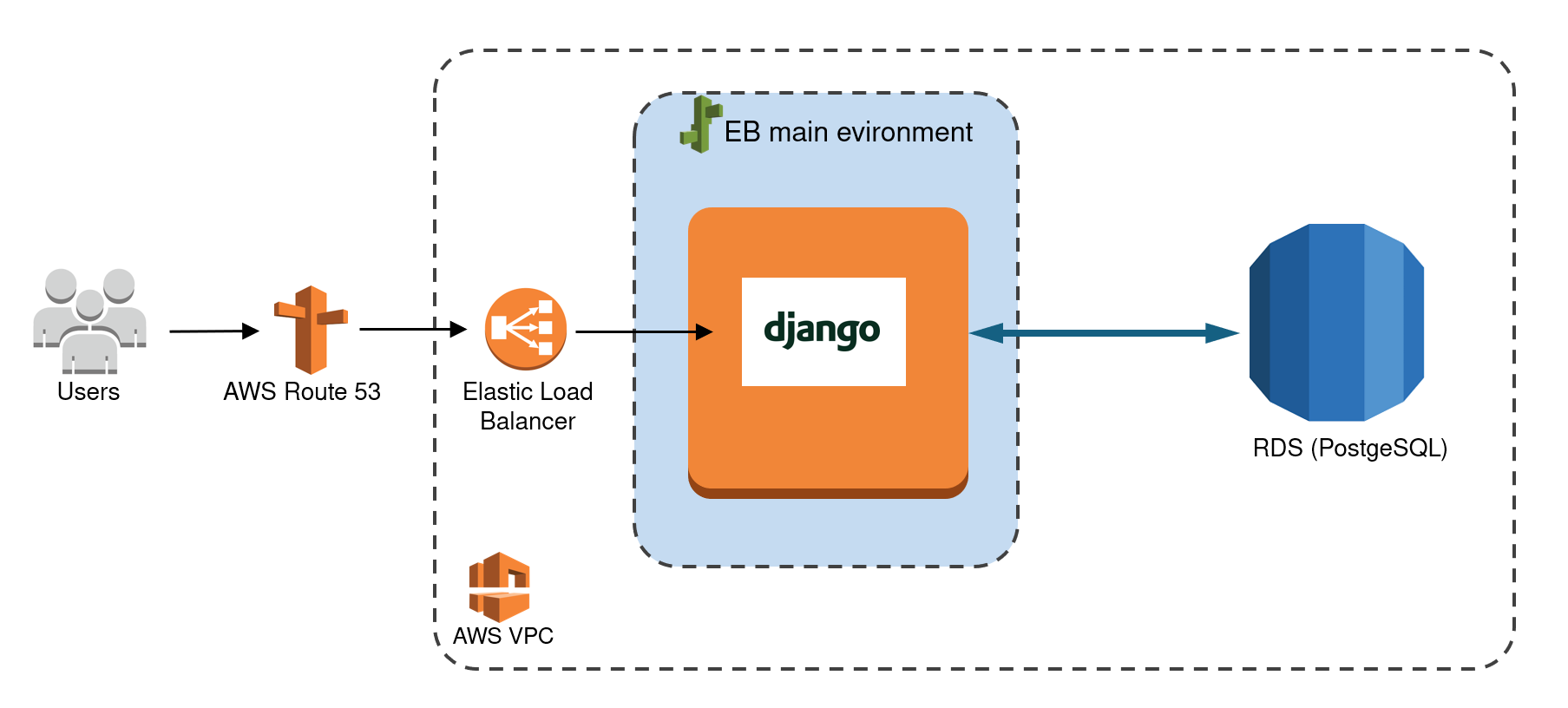
Migration from Heroku to AWS
This webservice/online platform had been hosted on servers from the Cloud Provider "Heroku".
The server was getting too slow for running intensive simulations and Heroku however only offers limited options for scaling. It was therefore necessary to migrate the webservice to AWS.
23rd February 2020
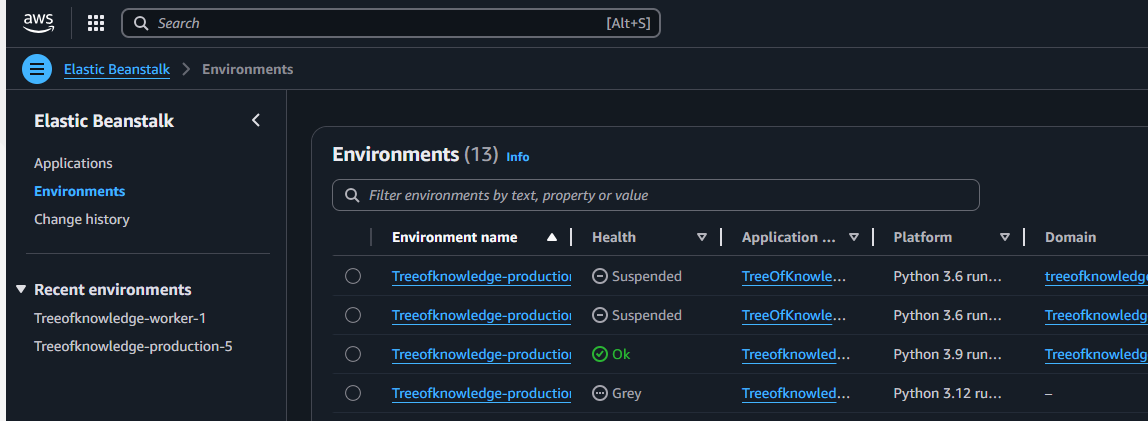
Admin Pages completed
In order to monitor and manage this online platform (especially the Knowledge Base), specific Admin pages were created which are only accessible for users with admin rights.
30th November 2019
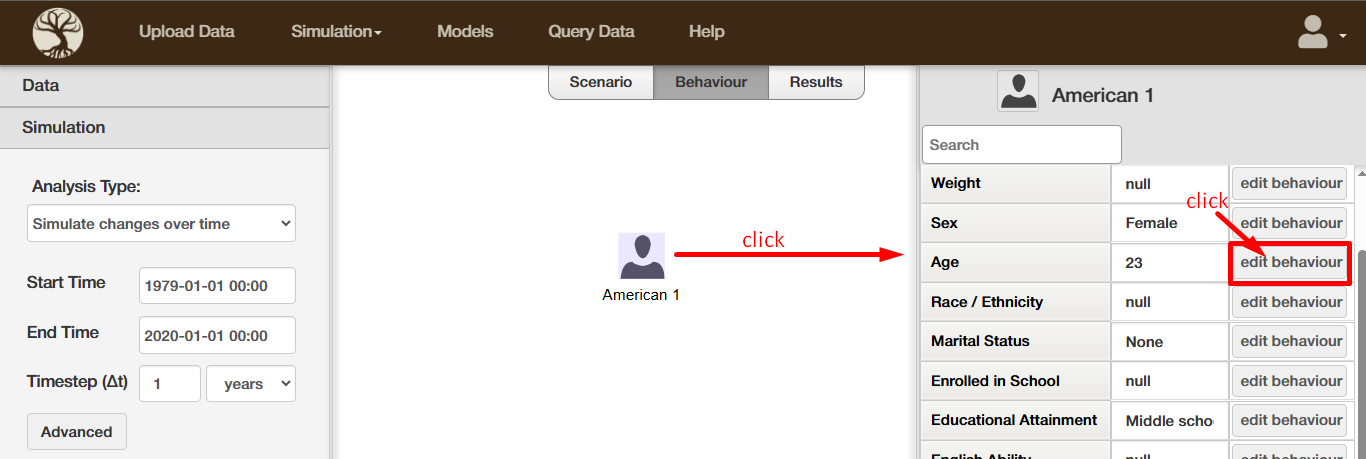
Result Inspector & Simulation Inspector completed
Result Inspector
These pages allow you to inspect the details of the Bayesian Inference.
Notably, they allow you to see
Simulation rules sometimes have unexpected consequences. It is therefore very important to be able to inspect every/any simulation in detail and see where it potentially went wrong...
From the Result Inspector pages (see last paragraph) you can select a simulation to be shown in more detail. The system will then re-run this simulation while exactly logging everything that occurs, and display the folllowing simulation details in the Simulation Inspector pages:
These pages allow you to inspect the details of the Bayesian Inference.
Notably, they allow you to see
- How well each simulation performed - how accurately the simulations mimicked the real world/ how well it reproduced the observed data.
- The parameter values that led to specific simulations working well/not so well
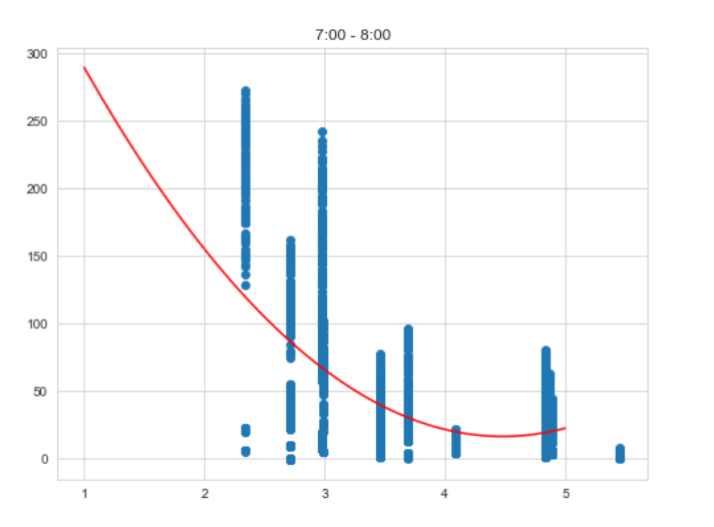
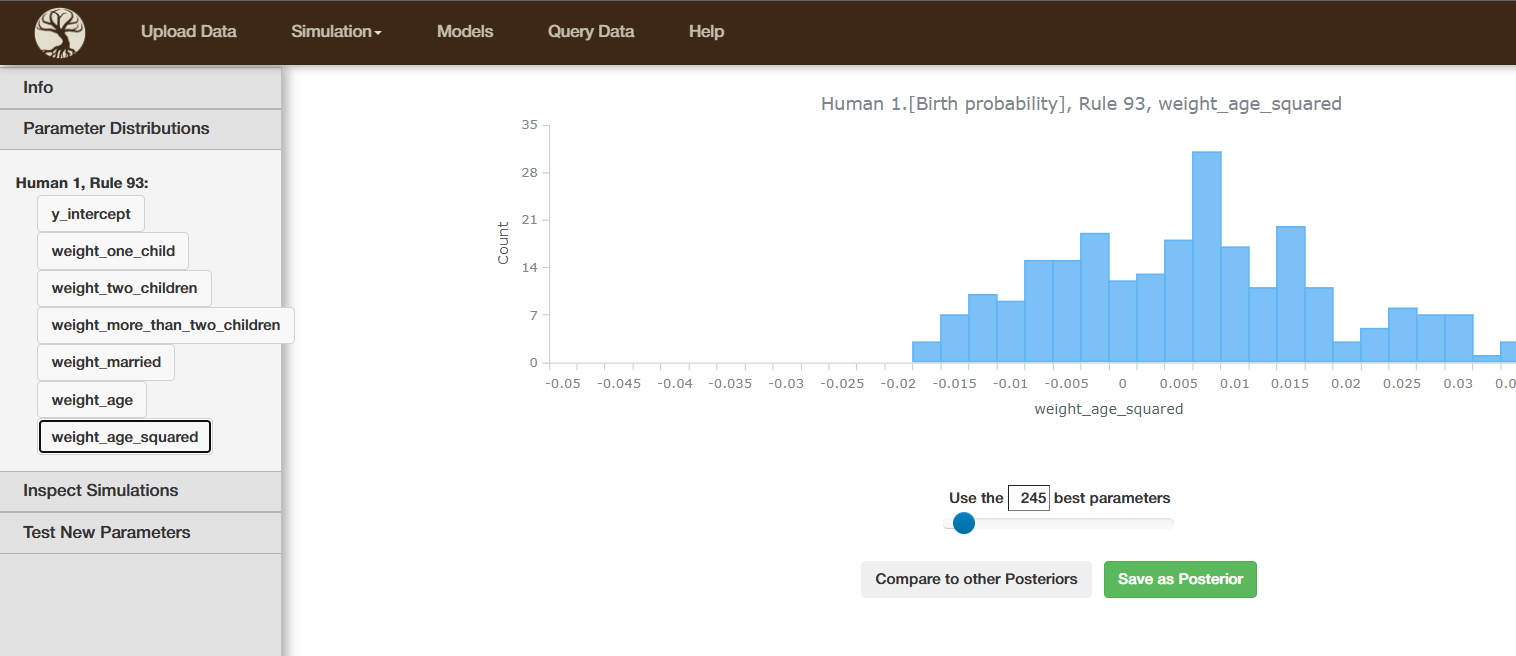
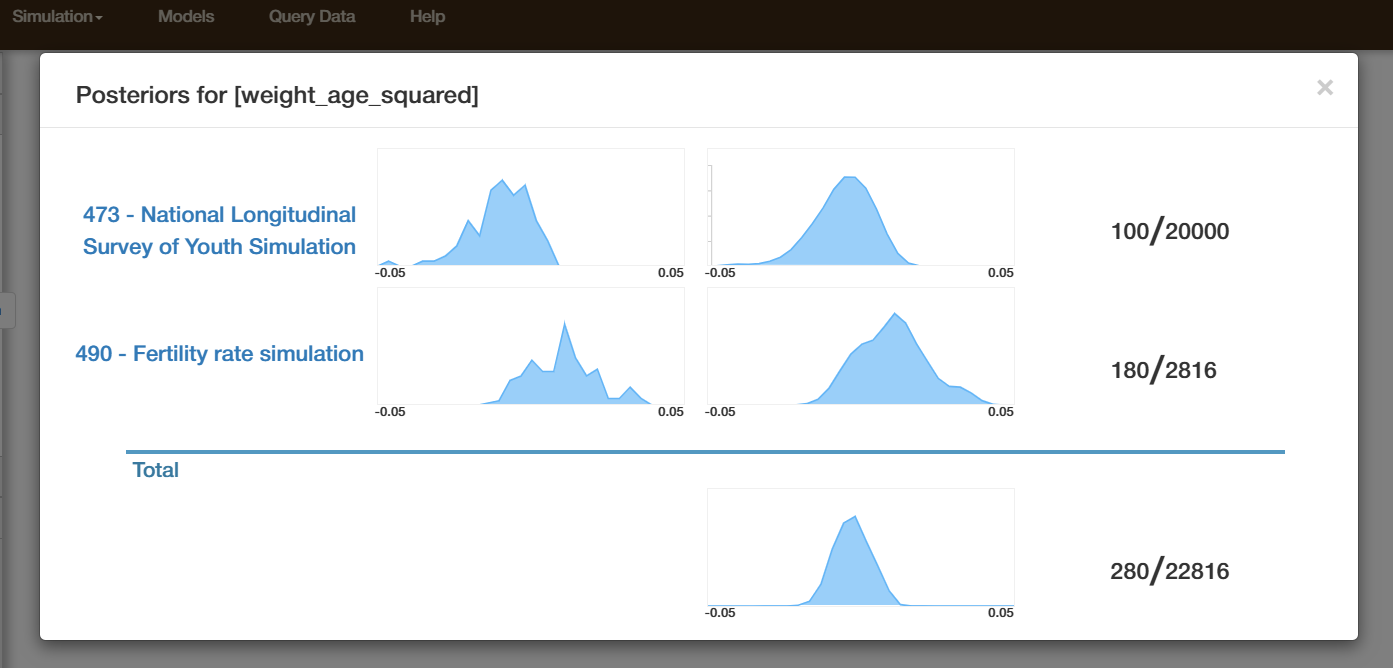
- Posterior distributions depending on the threshold ε
According to Approximate Bayesian Computation (ABC) logic, you can try out different values for the threshold ε and see how the posterior distribution is affected by this threshold.
Simulation rules sometimes have unexpected consequences. It is therefore very important to be able to inspect every/any simulation in detail and see where it potentially went wrong...
From the Result Inspector pages (see last paragraph) you can select a simulation to be shown in more detail. The system will then re-run this simulation while exactly logging everything that occurs, and display the folllowing simulation details in the Simulation Inspector pages:
- Comprehensive table of all values at all timesteps
- Graph to show the evolution of an attribute. It can also show this attribute evolution for many simulations simultaneously - allowing for comparisons and trend analysis
- Executed rules
For every timestep, it shows exactly which rules were executed in which order - allowing for detailled debugging
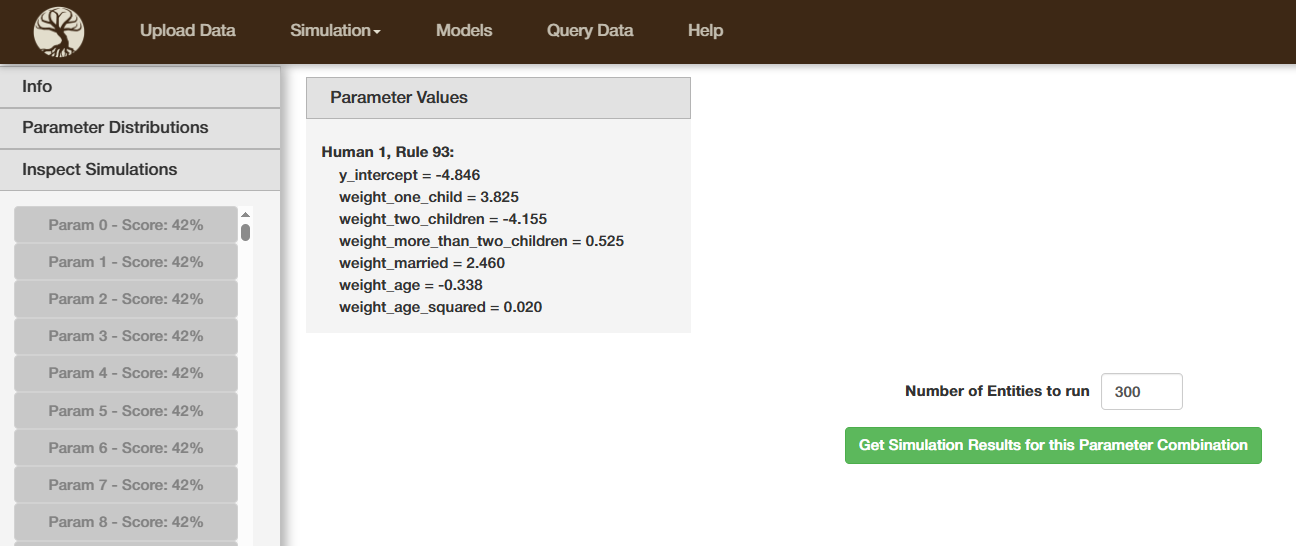
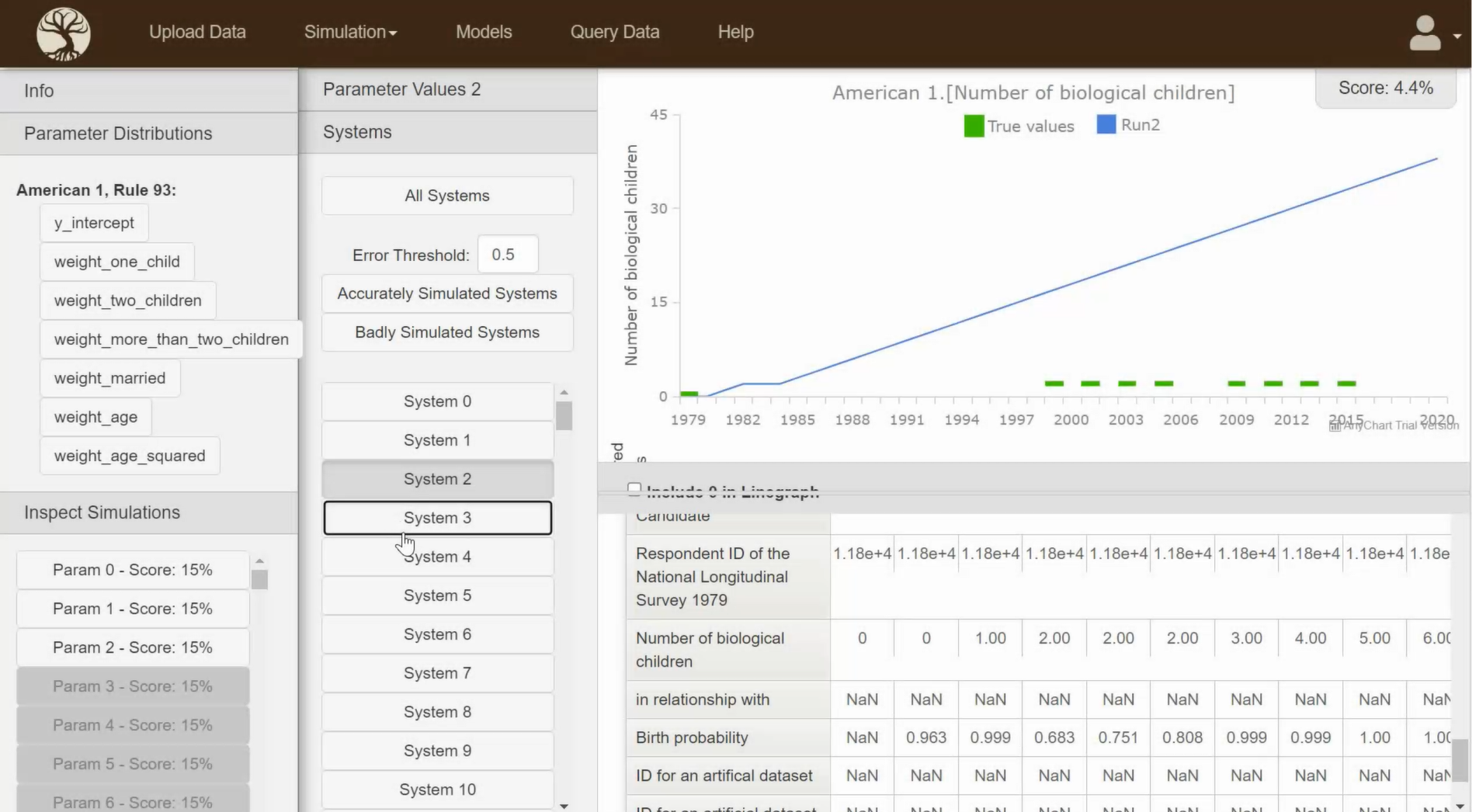
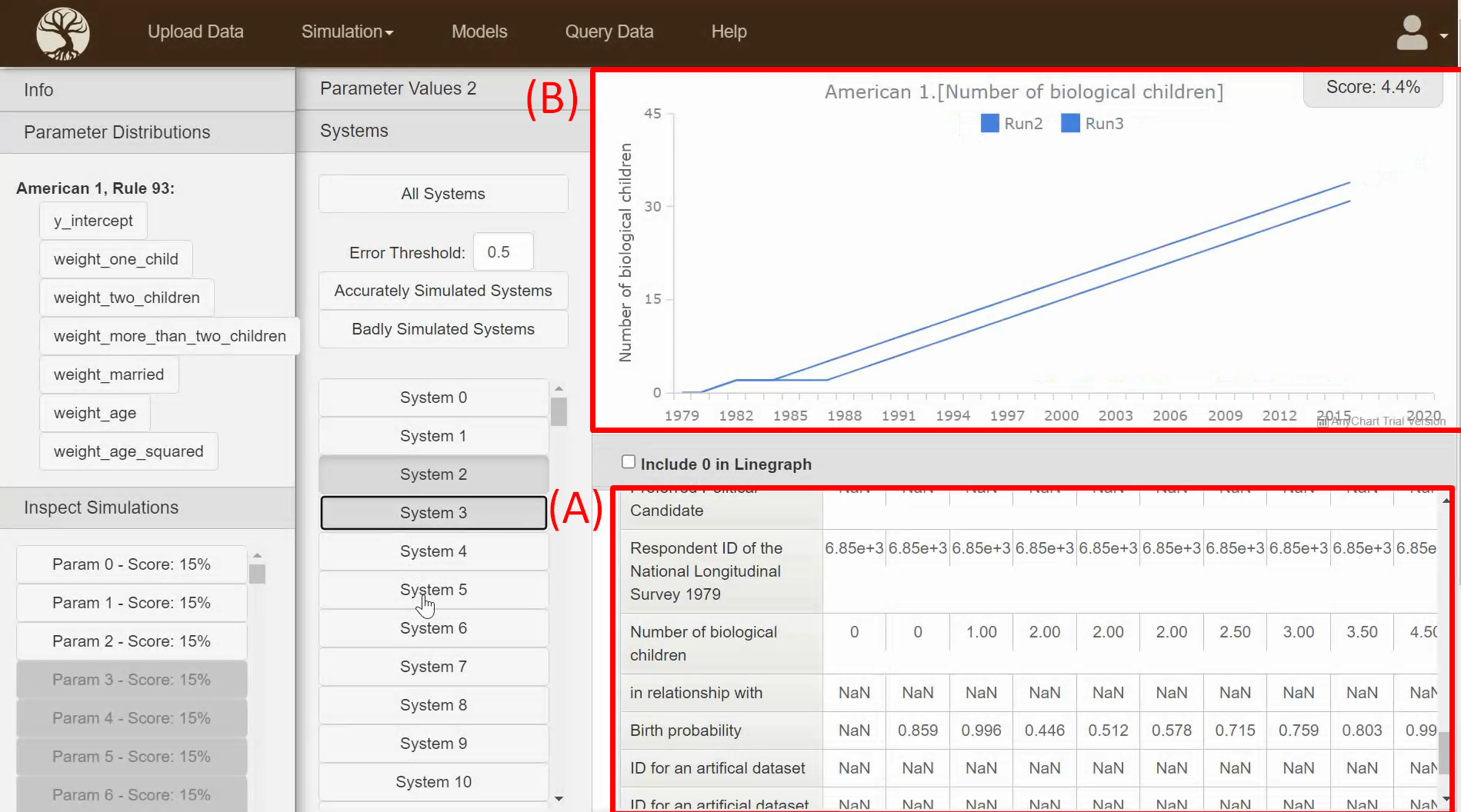
(B) Graph showing the evolution of whatever attribute you selected in table (A)
30th November 2019
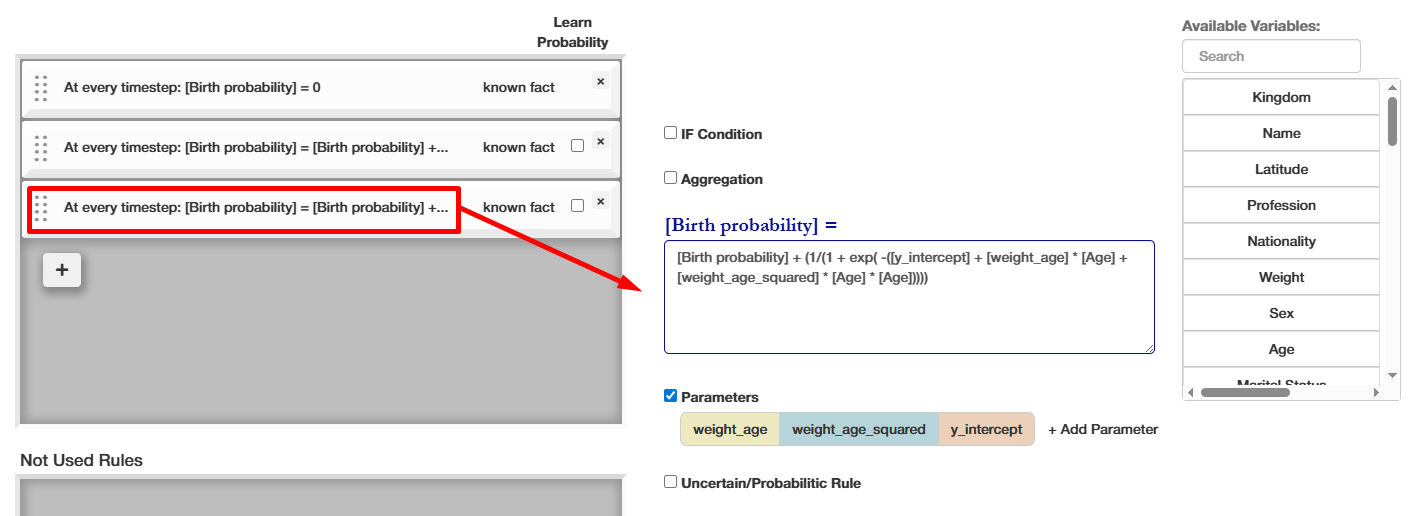
Rule Editor & Rule Parameters completed
The agent's behavior rules is what makes everything run. Tree of Knowledge's core mission is to find the correct behavior rules for humans and other social agents.
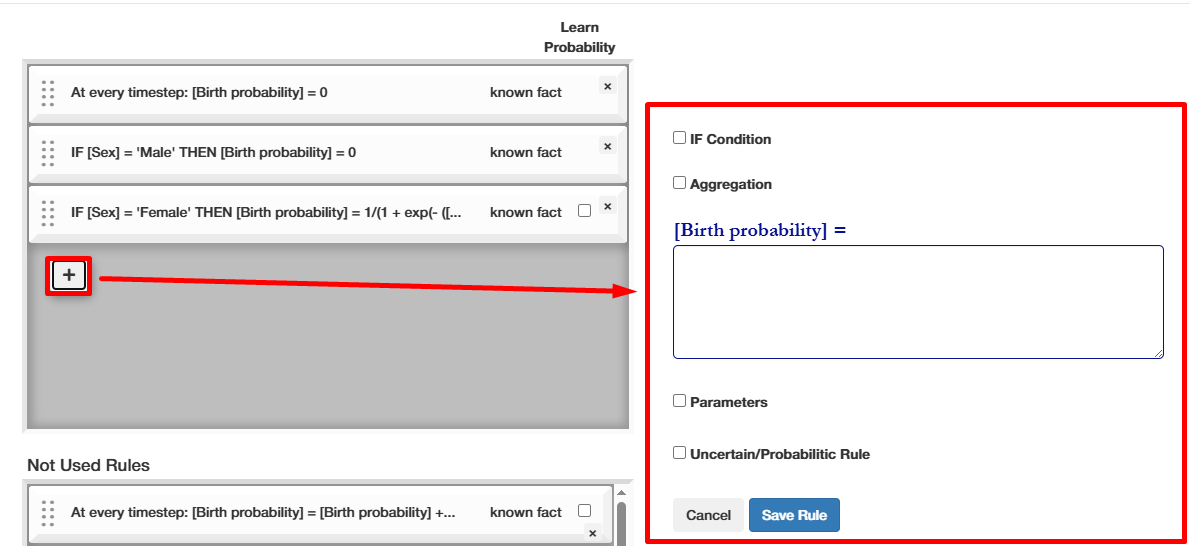
A Rule is a calculation of the next timestep's value for an attribute. To allow you to create versatile and expressive behavior rules, you have the following options:
A Rule is a calculation of the next timestep's value for an attribute. To allow you to create versatile and expressive behavior rules, you have the following options:
- "If Condition" - condition that has to be satisfied for the rule to fire
- "Parameters" - unknown rule parameters that will be inferred using Bayesian Inference
- "Uncertain/Probabilistic rule" - probability for the rule to trigger; also inferred with Bayesian Inference
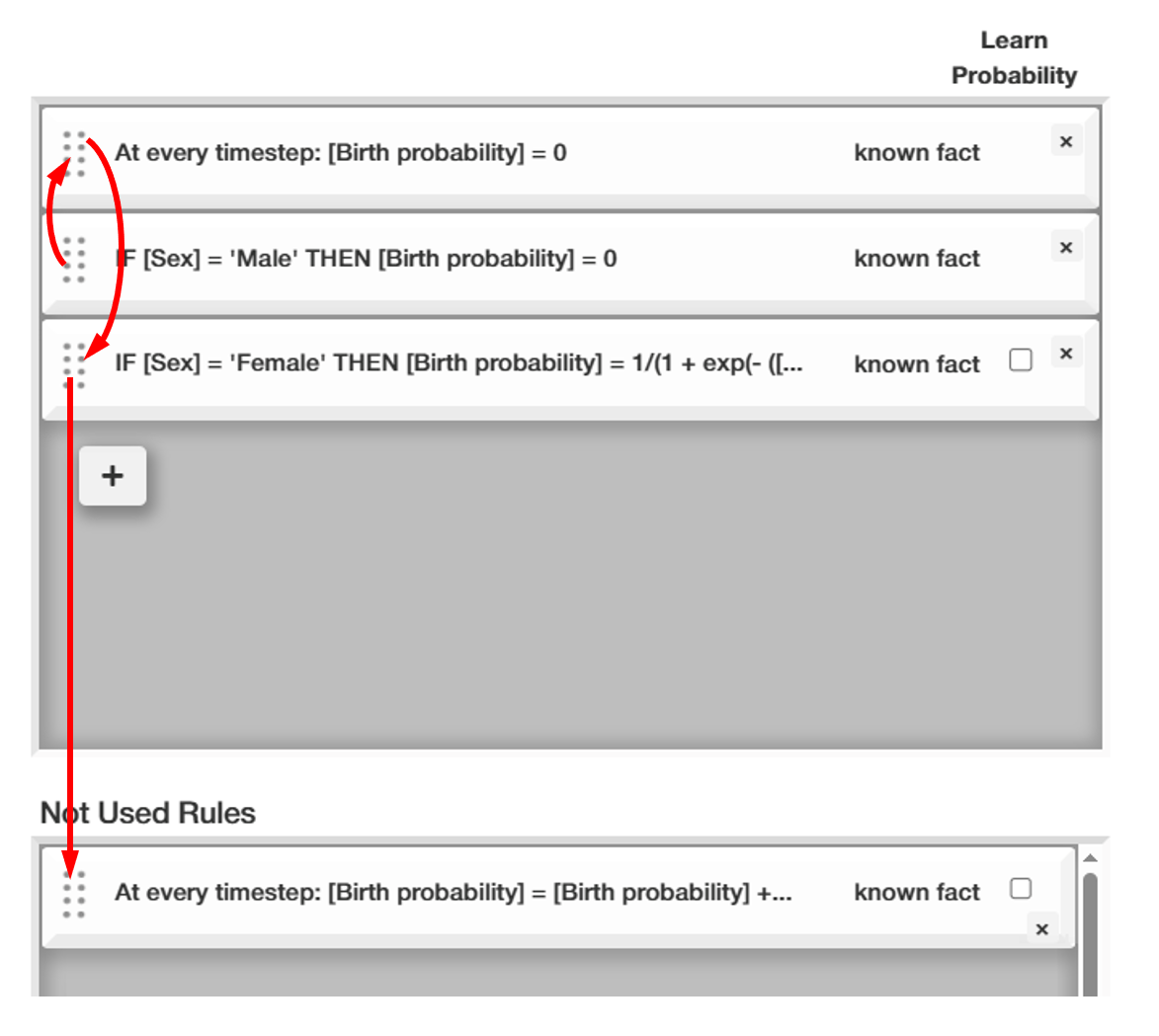
During the simulation, rules are executed after each other from top to bottom. By drag&dropping them, you can change the execution order or completely remove them from the next run.
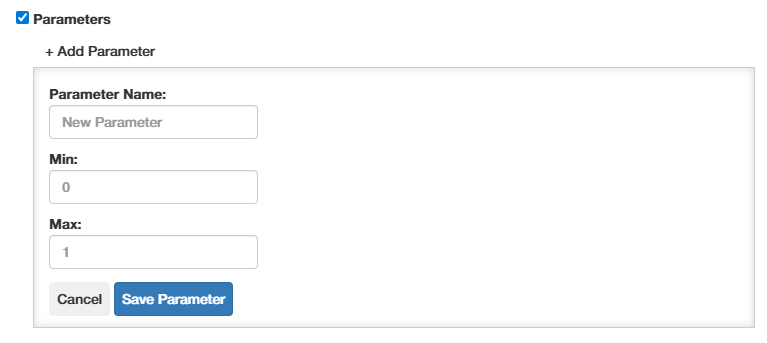
Currently, all rule parameters start off with a uniform prior in the predefined range (this might be extended in future). The prior distribution will however get updated with by the different inference runs (= dataset+models).
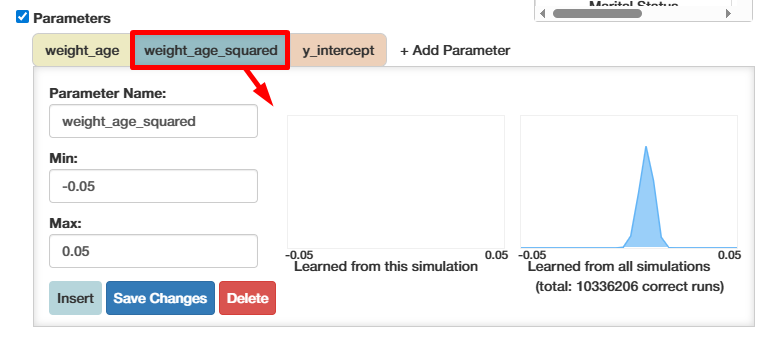
As you can see, the inferred posterior is displayed, too

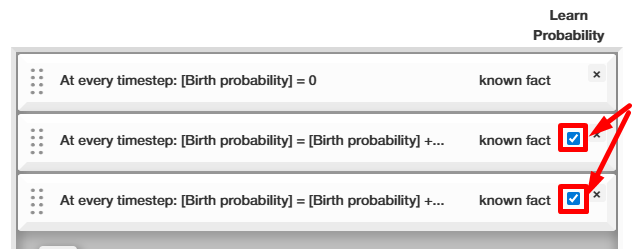
By selecting only 1-2 rules for inference, the number of to-be-inferred parameters is kept low. This is critical for keeping the inference time low, which starts balooning with more than seven parameters.
12th August 2019
Simulation editor created
With the Simulation Editor, you can specify the initial configuration of a simulation
This can be down for two reasons:
When creating behavior rules you had the option to use one or more of the following options: As far as we can tell, you now are able to define absolutely any behavior rule you could think of.
This can be down for two reasons:
- Make a simulation that mimicks the real-world environment in which a dataset was captured
When creating behavior rules you had the option to use one or more of the following options: As far as we can tell, you now are able to define absolutely any behavior rule you could think of.
12th January 2019
Knowledge base created
Behavior rules calculate the next timestep's value for a variable, using any of the current actor's own attributes or attributes of an agent related to the current actor.
When creating behavior rules you had the option to use one or more of the following options: As far as we can tell, you now are able to define absolutely any behavior rule you could think of.
When creating behavior rules you had the option to use one or more of the following options: As far as we can tell, you now are able to define absolutely any behavior rule you could think of.
Newsletter