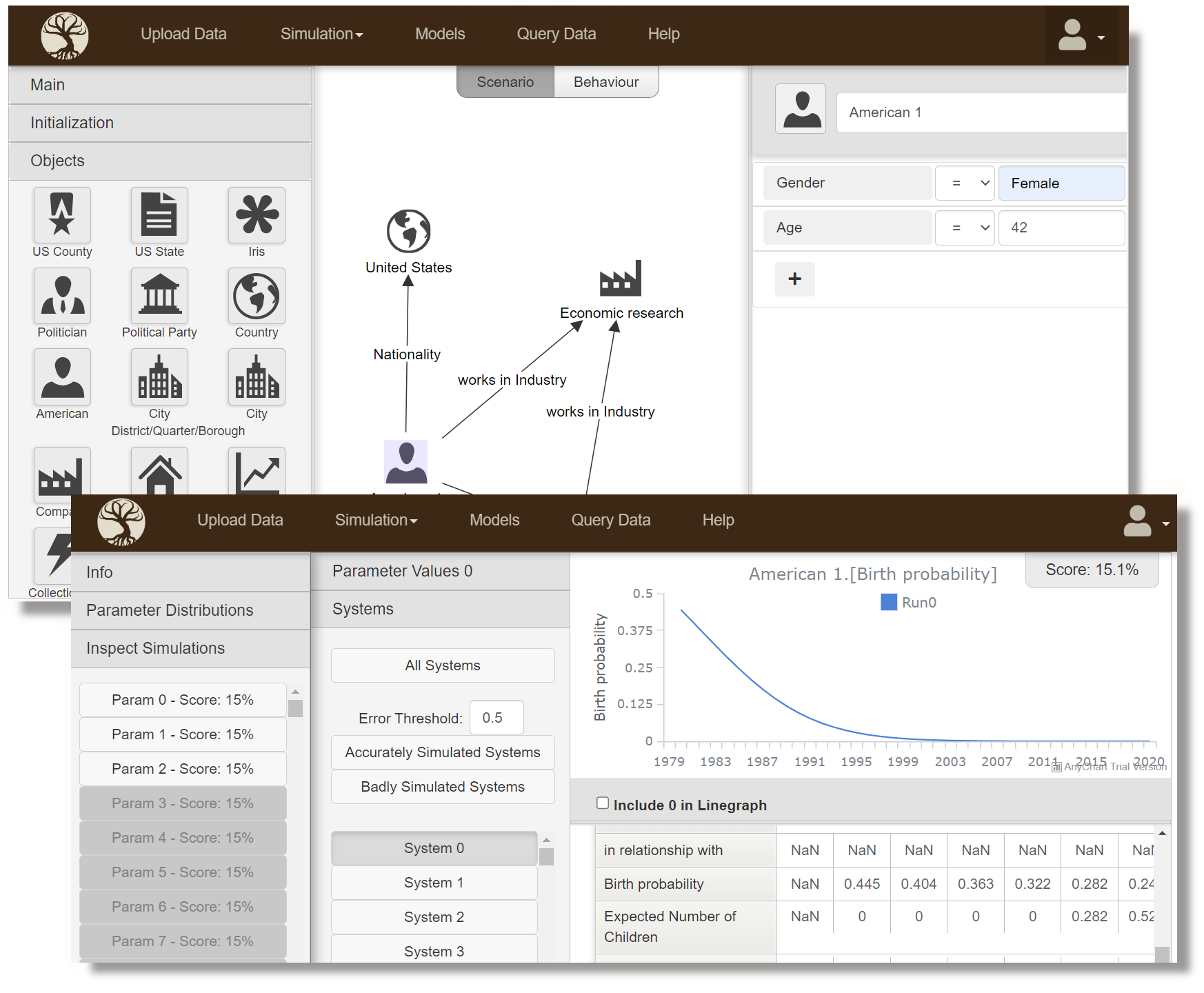
Create a New Era in Social Science Research
By developing the world’s first formal theory of social systems.
The Big Problems with Statistics
Statistics is the main tool for doing quantitative social science research.
Unfortunately, it is very badly suited for dealing with the complex social systems and phenomena that exist in the real world:
Unfortunately, it is very badly suited for dealing with the complex social systems and phenomena that exist in the real world:
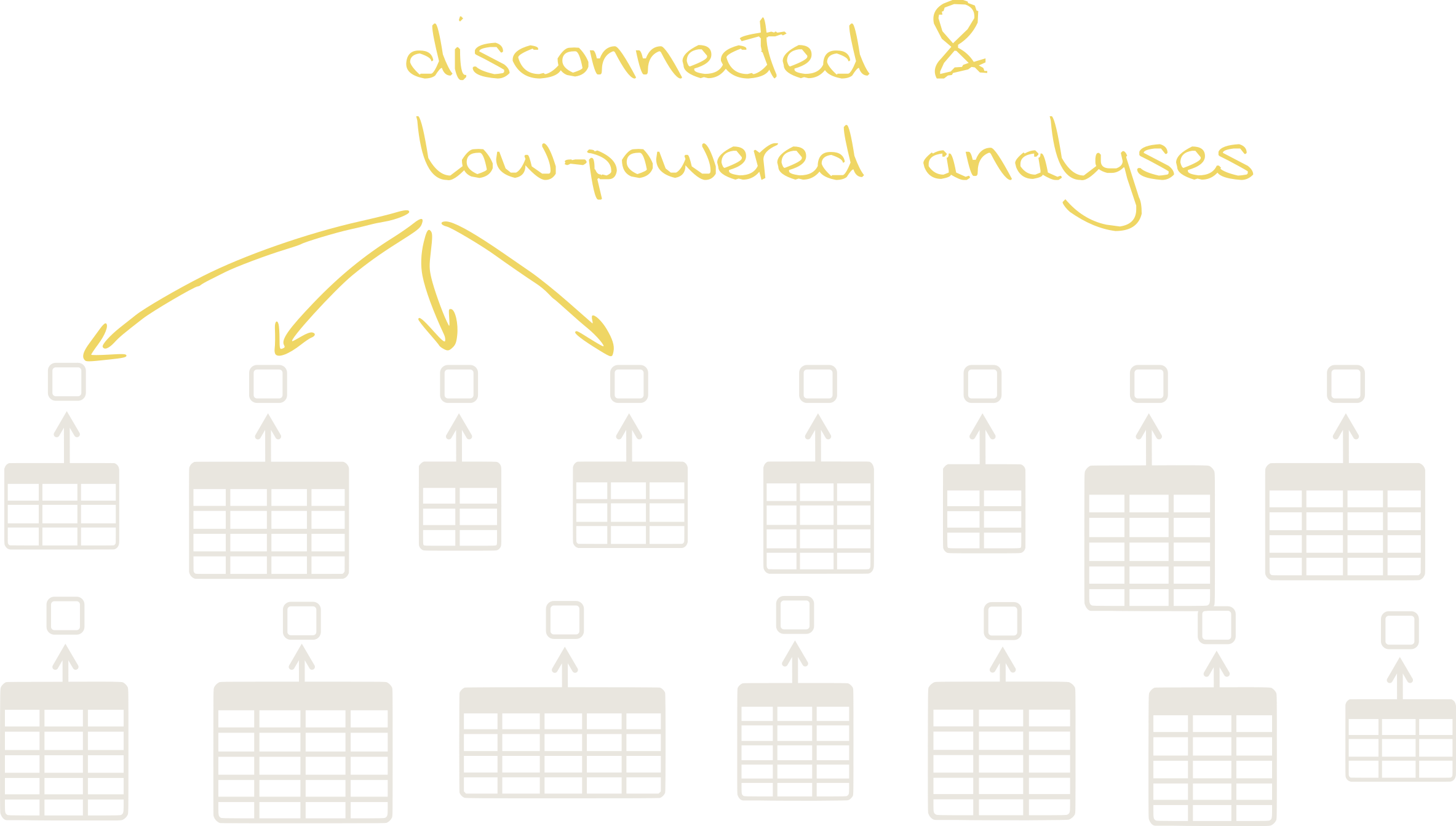
- Statistical analyses are always based on only a single dataset, making them unreliable/not well proven and not generalisable.
- Statical models cannot deal with real-world complexities, limiting us to analysing studies made in very artificial environments.
- The individual analyses and the resulting findings are completely disconnected from each other. Instead of our understanding progressing, we therefore just get an ever-growing jumble of inconclusive and partially-contradictory findings.
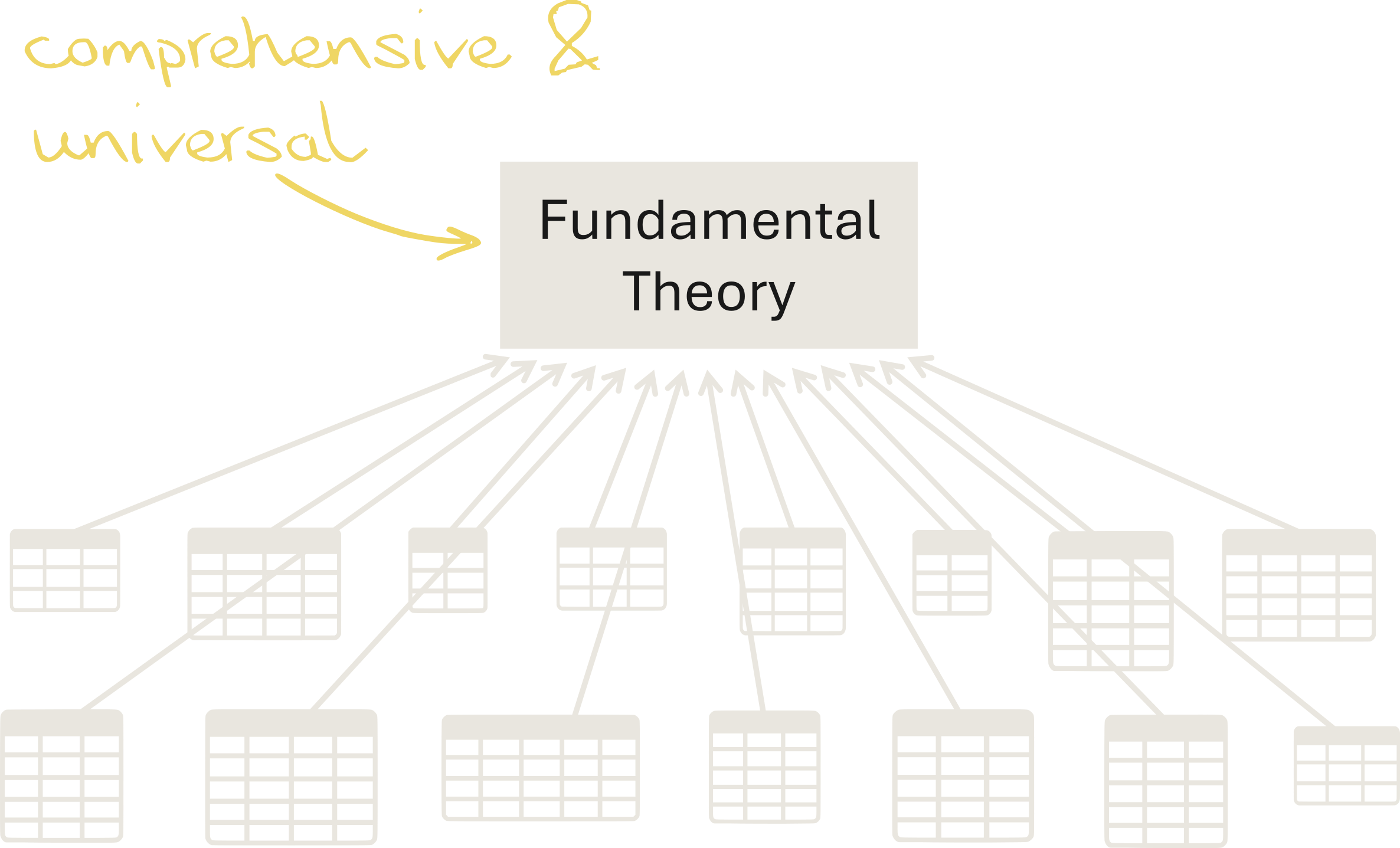
The Solution: Fundamental Theory Building
This online platform enables a completely new approach to statistics - instead working on isolated findings, researchers can now collaborate to develop a powerful fundamental theory that fits all datasets.
⟶ Benefits
- Training a model on many datasets - instead of just a single dataset - gives us insights which are vastly more proven, accurate and generalisable.
- By integrating with the work from other researchers, you can model and capture highly complex phenomena and get a detailed and insightful understanding.
- Through modelling datasets on this platform, you are automatically helping to improve and extend the world's first exact fundamental theory of human behavior.
⟶ About Fundamental Theories
Fundamental theories are extremely powerful!
For example, a fundamental theory of human behavior would not only give us an accurate and complete understanding of human behavior. It would also allow us to predict the exact behavior of any absolutely social system - thereby automatically solving most social science research questions.
For example, a fundamental theory of human behavior would not only give us an accurate and complete understanding of human behavior. It would also allow us to predict the exact behavior of any absolutely social system - thereby automatically solving most social science research questions.
How it works
The powerful fundamental theory will continue to improve over time,
but even from the very start there are massive advantages to this new approach.
Such as...
Advantages
Continuous & Measurable Progress
Video Summary:
Working with a fundamental theory is a lot easier and less work than having to make sense of a large collection of individual insights. It gives us a cohesive and complete understanding and allows us to make exact predictions for any scenario.Most importantly, the rigorous evaluation framework allows us to objectively determine which candidate theory is the best - this is the key to real, measurable and lasting scientific progress!

Reliable & Universal
Video Summary:
Confidence in scientific findings comes from the finding but from it being shown to hold true in many circumstances.Tree of knowledge tests hypotheses in hundreds of different scenarios, making them orders of magnitudes more reliable and trustworthy than the findings from normal statistical analyses. Also, this rigorous testing assures the general applicability/universality of these results.

Understanding complex systems
Video Summary:
With current statistics it is very hard to model complex systems - instead of creating complex models, we make simple models and rely on randomisation to cancel out all the "disrupting effects" (such as differences between study participants). While this is a viable approach, the randomisation introduces incredible amounts of noise to the data - making the study of most phenomena impossible.With all the already-modelled phenomena in Tree of Knowledge, it becomes very easy to make complex models that capture all the complexity and no longer rely on randomisation.
Opening up for study: vast, previously-too-noisy areas of reseach.
Frequently Asked Questions
The differences between people are taken into account in the different behavior rules we create.
E.g. the trigger for the action “tidy the house” should depend on a person's hygiene level. Which in turn might depend on other things.
E.g. the trigger for the action “tidy the house” should depend on a person's hygiene level. Which in turn might depend on other things.
I believe that having a low accuracy (= wide uncertainty) isn't a bad thing.
Being trained-on and optimized to hundreds of datasets, makes Tree of Knowledge the most accurate fundamental theory out there. If the most accurate existing theory says that there is a high uncertainty attached to a specific prediction, then we can be fairly confident that this is truly the case.
I think that being honest about the limits of our knowledge in this way is very important and is a refreshing change to some of the alternatives - both hypothesis tests and popular rethoric have a strong tendency to overstate their confidence in predictions.
Being trained-on and optimized to hundreds of datasets, makes Tree of Knowledge the most accurate fundamental theory out there. If the most accurate existing theory says that there is a high uncertainty attached to a specific prediction, then we can be fairly confident that this is truly the case.
I think that being honest about the limits of our knowledge in this way is very important and is a refreshing change to some of the alternatives - both hypothesis tests and popular rethoric have a strong tendency to overstate their confidence in predictions.
This is a problem that psychology and similar disciplines have faced for a long time. There is a consensus on how to deal with these difficulties, which are described in the field of measurement theory. Tree of knowledge recommends sticking to this consensus.
However, this platform will allow us to see which rules most accurately describe human behavior… it might turn out that things work differently after all.
However, this platform will allow us to see which rules most accurately describe human behavior… it might turn out that things work differently after all.
Revolutionizing Social Sciences